
Продолжение серии постов по поиску скрытого кода. Имеет смысл поразбираться с понятием на паре примеров.
Вообще говоря, примеры сыроватые — хотя и любопытные. Напомню, смысл всего мероприятия основывается на том, что:
- Машина Тьюринга вычисляет всё что вычисляется,
- Рекуррентные нейросети эквивалент машины Тьюринга,
- Сильный вид гипотезы в том, что если возможно рекуррентной нейросетью прогнозировать ситуацию «после», то это означает её вычисления эквивалентны выполнению самого действия.
- Скрытый код — число, которое содержит в себе (в дискретном пока случае) описание всей ситуации «после» (как и «до» тоже).
Вычисляется скрытый код по такой процедуре:
def hidden_code(start, finish, weights):
return sum([
weights[index] * np.log(
start[index]**start[index] / finish[index]**finish[index]
) for index in range(len(start))
])Возникает (естественный) вопрос, а зачем ситуация «до»? Логически, скрытый код не должен быть одним и тем же для одного конечного результата в случае когда стартовали из разных ситуаций, поэтому.
Пример с нечестной монеткой
Допустим есть у нас монетка, которая падает в орлом в 20% случаев, а решкой — в остальных 80% (на ребро пусть не падает). В этом случае у нас «стартовое положение» это x1 = 0.2, x2 = 0.8.
Мы что-то предпринимаем в этом несовершенном мире, чтобы сделать его поровнее, что ли, и монетка начинает падать как y1 = y2 = 0.5.
Наши предпочтения в данном случае выражаются весами (+1, +1). В этом случае можно и скрытый код подсчитать, C ~ +0.19. Положительные значения говорят о том, что мы движемся в нужном нам направлении, так как по определению скрытый код это разница между будущим и прошлым «положением вещей», по сути в наших весах мы создали больше нужной информации.
Допустим мы всё так же хотим сделать монетку честной (+1, +1), но по факту мы достигли обратного: y1 = 0.1, y2 = 0.9. В таком случае C ~ —0.17. Если бы это было бы (неравнозначно) желаемым направлением, с весами (+1, -2), то C ~ +0.07.
Для случая же «падает только решка» (от изначально честной монетки 50/50) в весах (+1, +1), мы получим C ~ —0.69. С обратными весами, по построению, это же число будет положительным.
Это всё примитивная интерпретация нелинейной формулы, так или иначе всё зависит от весов, определять которые нужно (страшное слово) экспертно. Но для ознакомления уже что-то.
Набор данных трендовых видео
Сейчас пойдут картинки. Вообще, найти такой датасет, чтобы скрытый код можно было бы посчитать — само по себе некоторая задача. Конкретно в этот раз взят датасет с Kaggle YouTube Trending Videos, в которым были видео, попадавшие (по алгоритмам площадки) в раздел трендовых.
Для них есть лайки, дизлайки и просмотры, последние я заменил на разницу просмотров и лайков с дизлайками, — в предположении что это воздержавшиеся. Будучи поделенными на общее количество их можно рассматривать как оценки вероятностей.
Простой рекуррентной нейросетью, на входе которой 8 прошлых значений скрытого кода, тут попытка спрогнозировать следующее значение. Проделано это было для RU-видео: ТОП1, ТОП10, ТОП30, и для ТОП30 US. Тренировочное и тестовое множества были отложены как 50/50, а веса были без особых выдумываний выбраны как (+1, -1, +1).
А теперь — слайды!
Упоминавшийся ранее код теперь приобретает законченное описание 🙂
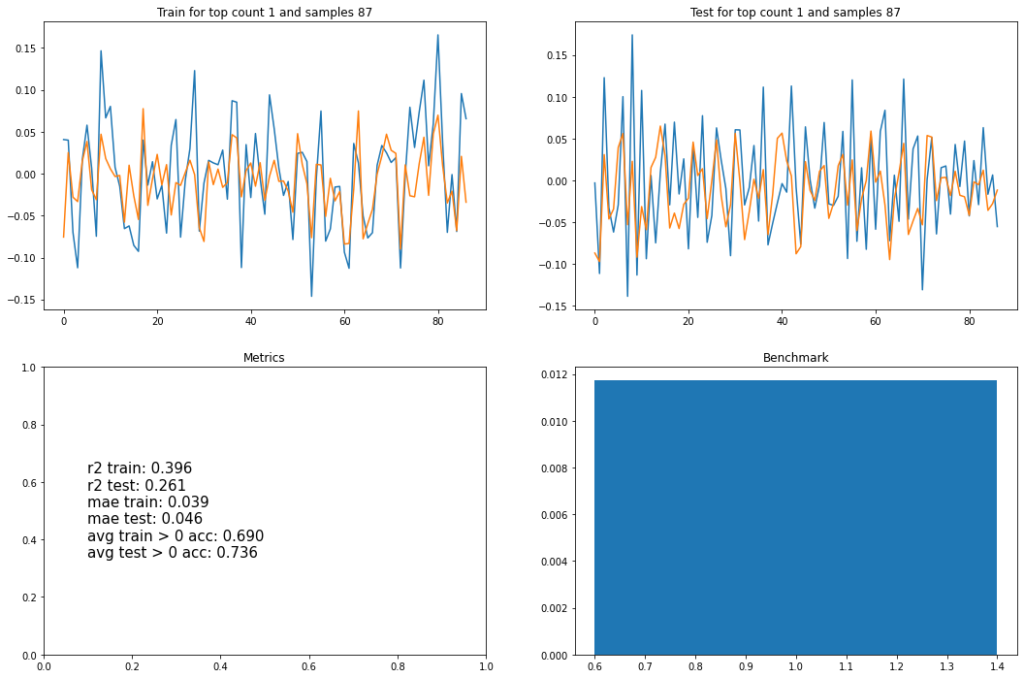
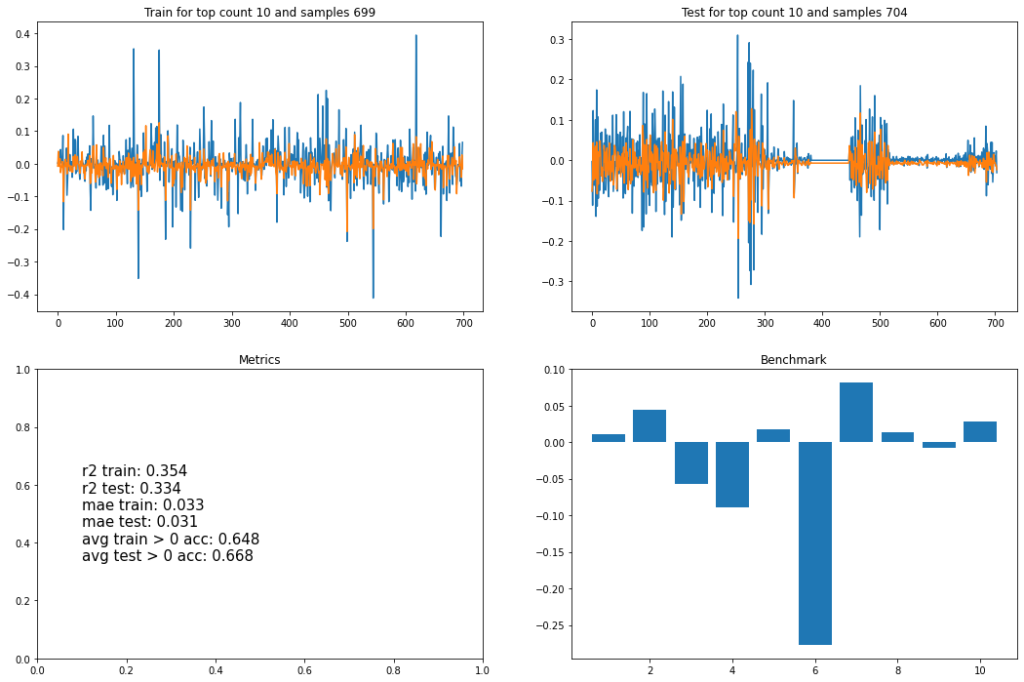
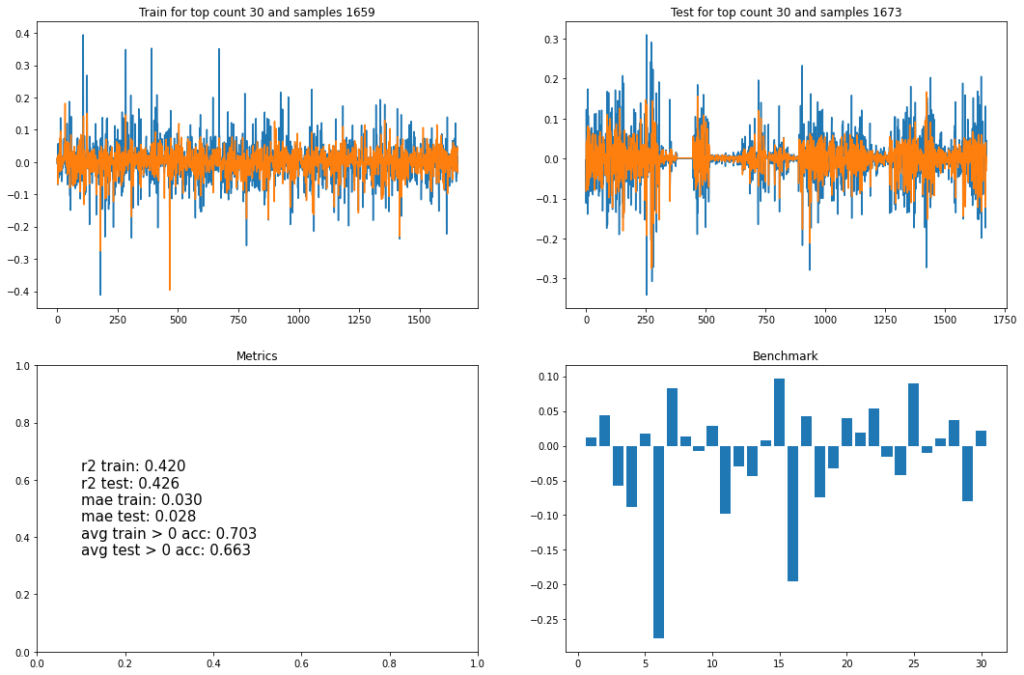
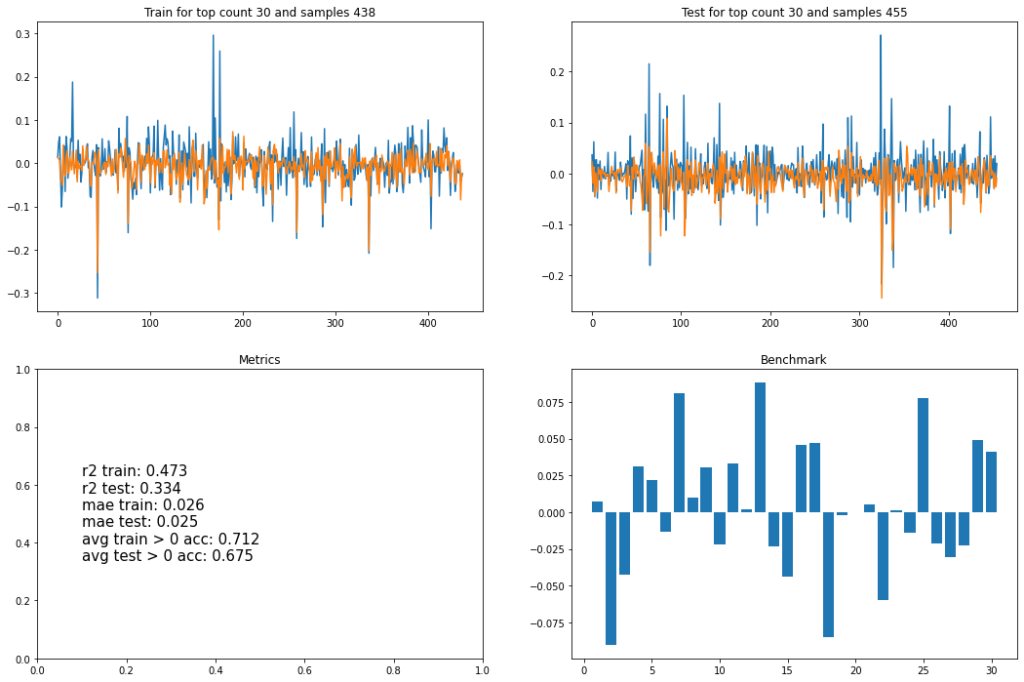
Что тут следует отметить:
- R2 — условно процент объяснения вариативности данных моделью практически у всех одинаковый, на уровне 30-40%. Модель где-то даже слегка переобучилась — но она была одна на всё про всё, что конечно же упрощение дел.
- В среднем со знаком модели не ошибаются в порядка 70% случаев.
- Справа внизу, диаграмма на горизонтальной оси которой отложены каналы по убыванию количества видео (в трендовых), а по вертикали — суммарный скрытый код. Корреляции не наблюдается, а это значит что (для выбранных весов) алгоритм для попадания в тренды не несет «светлого-доброго-вечного».
Скрытый код — не видно, а он есть
если у тебя нет паранойи, то это не значит что за тобой не следят
Это всё некоторое свидетельство в пользу скрытого кода, не доказательство конечно. Вообще, на одном датасете обобщающих выводов сделать нельзя, но вывод что концепт имеет право на рассмотрение — можно.
Еще подозрения
Сумму скрытых кодов брать весело, но несмотря на веса, это переход из самой изначальной точки в самую конечную, эквивалент. Само же «движение» скрытого кода вполне может представлять жизненный цикл, и проверять такое надо не на профильтрованном наборе данных, как трендовых видео, а на изначальном.
Если есть какие предложения по подходящим наборам данных, они приветствуются!
Предлагать можно в комментарии.